I’m proud to share HealthBench, an open-source benchmark from our Health AI team at OpenAI that measures LLM performance and safety across 5,000 realistic health conversations.
Unlike previous narrow benchmarks, HealthBench enables meaningful open-ended evaluation through 48,562 unique physician-written rubric criteria spanning several health contexts (e.g., emergencies, global health) and behavioral dimensions (e.g., accuracy, instruction following, communication).
We built HealthBench over the last year, working with 262 physicians across 26 specialties with practice experience in 60 countries (below), across selecting focus areas, generating relevant and difficult examples, annotating examples, and validating every step along the way.
Evaluation results
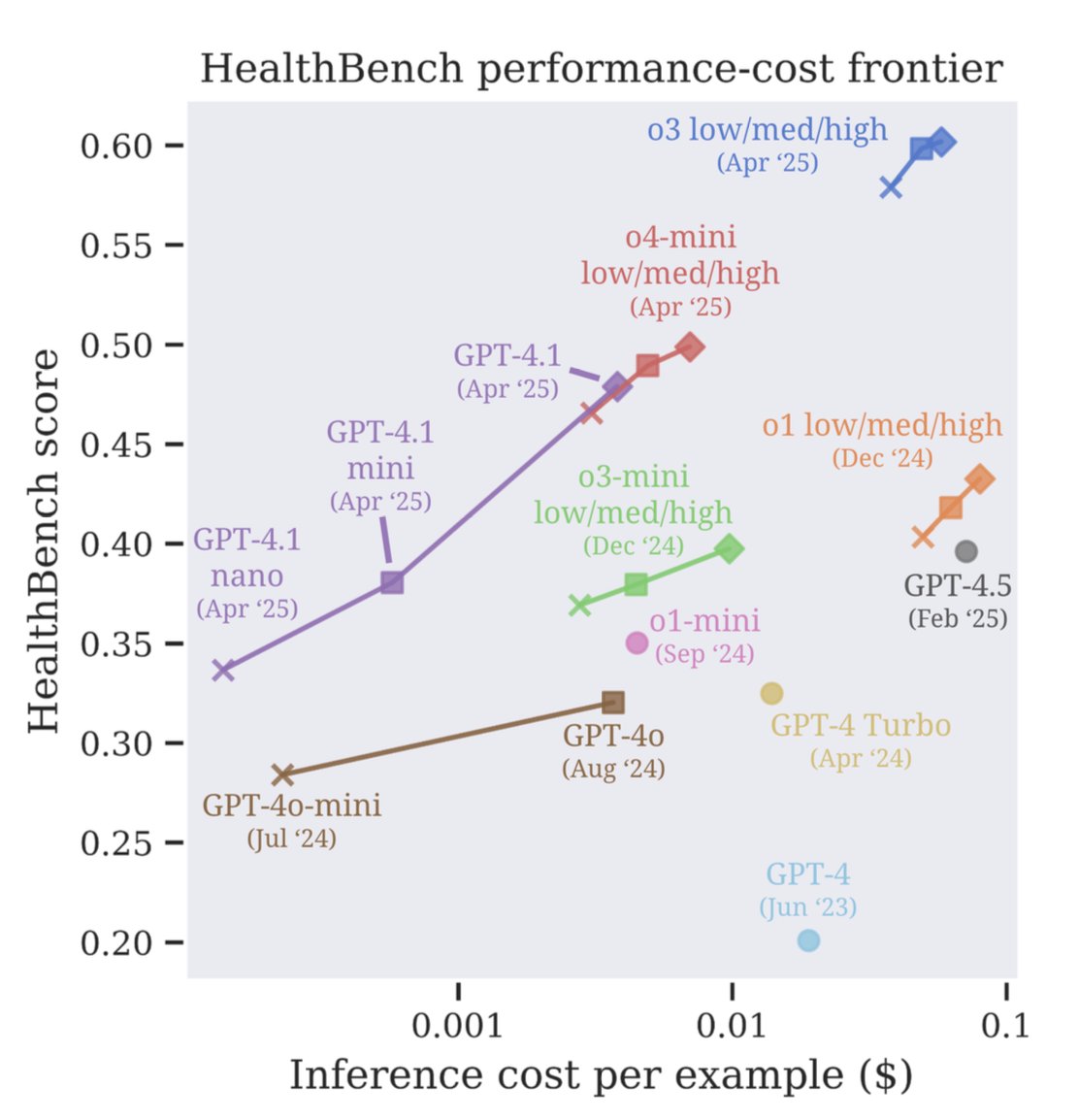
Using HealthBench, we see that our Apr 2025 models define a new frontier of performance at cost, with GPT-4.1 nano outperforming GPT-4o (Aug 2024), despite being 25x cheaper. The difference between o3 and GPT-4o (.28) is greater than between GPT-4o and GPT-3.5 Turbo (.16).
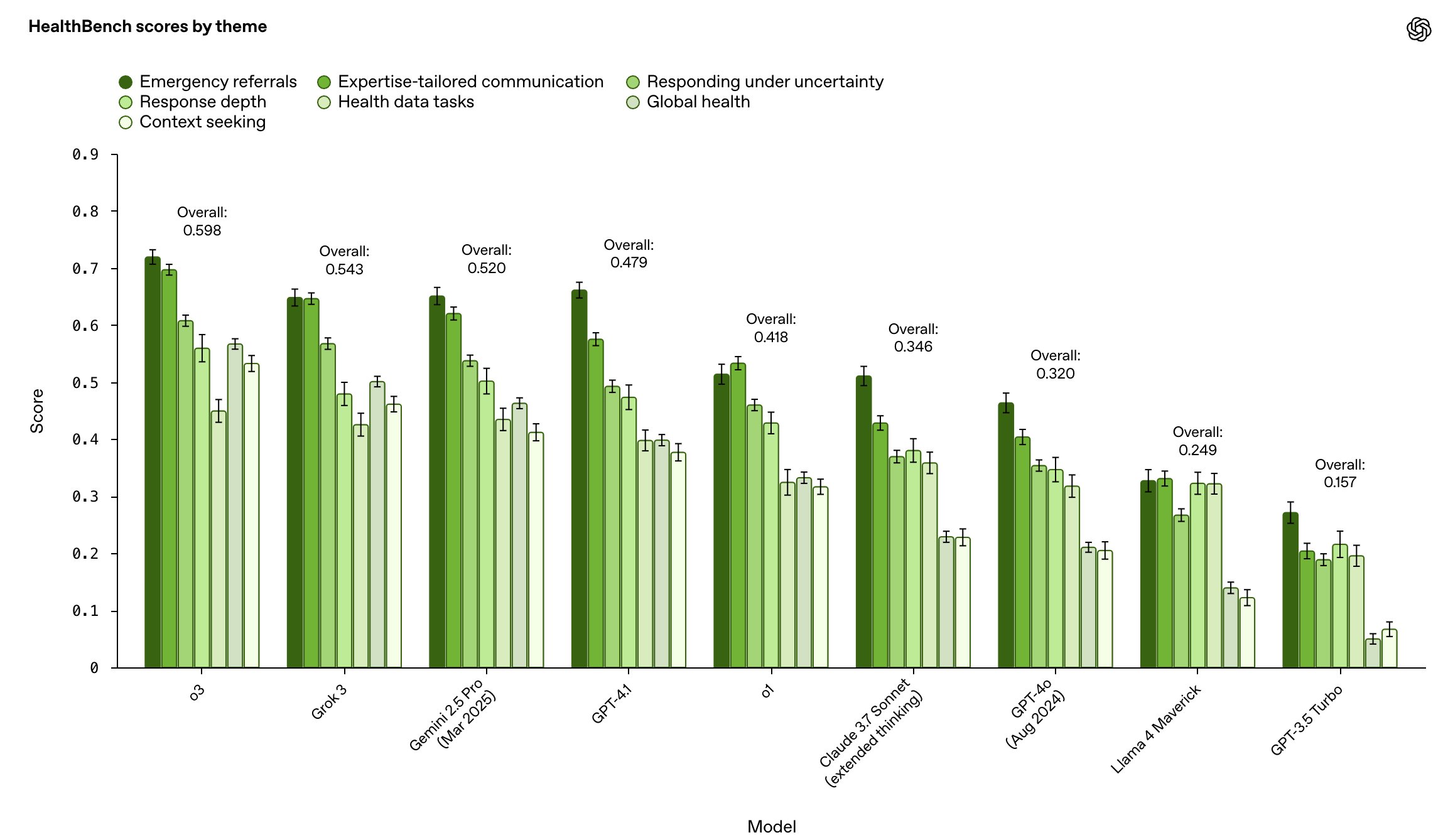
We compare our models to those of other model providers, stratified by focus areas. o3 performs best overall but headroom remains.
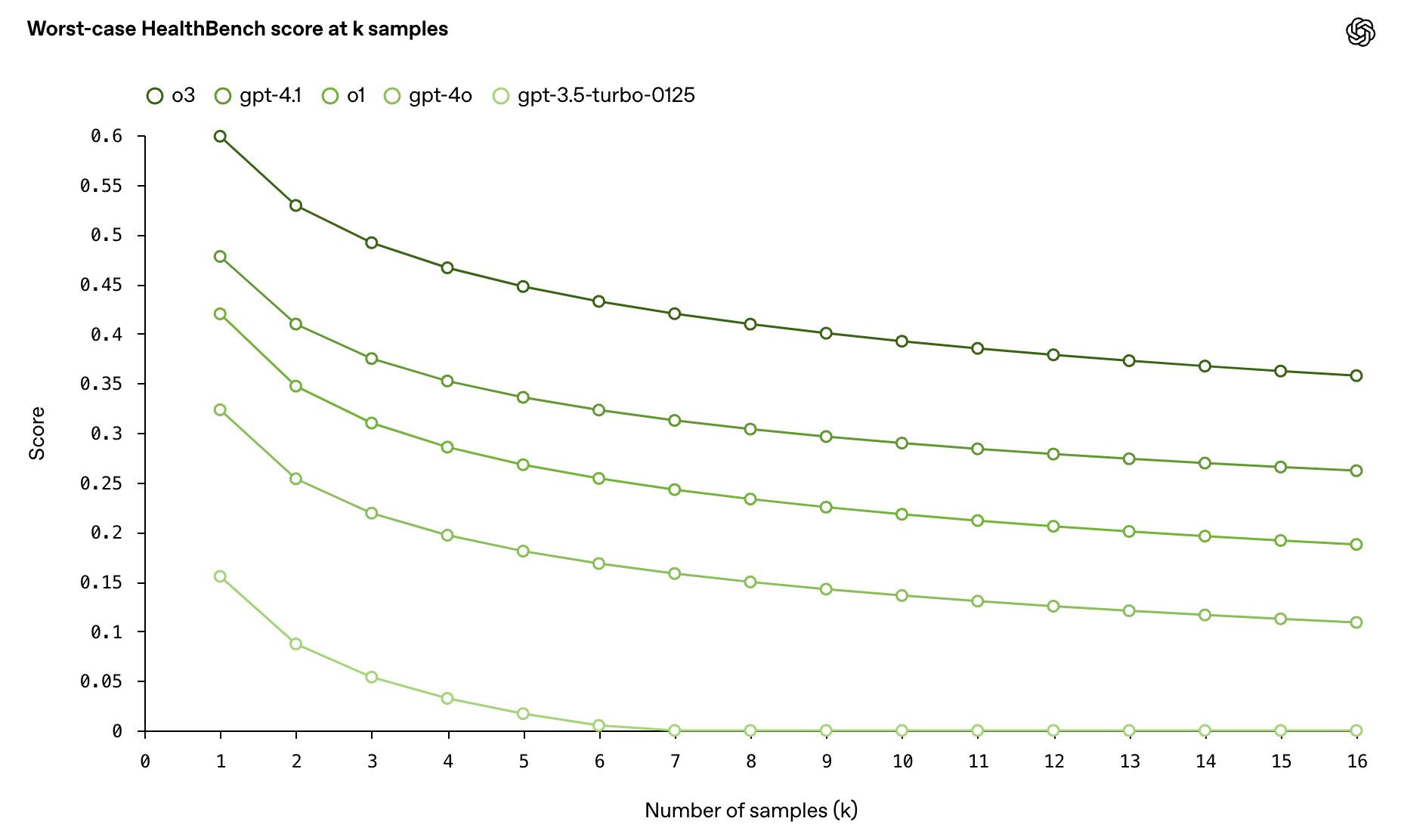
Reliability is critical in healthcare–one bad response can outweigh many good ones. We measure worst-case performance at k samples across HealthBench, and find that o3 has more than twice the worst-case score at 16 samples compared to GPT-4o.
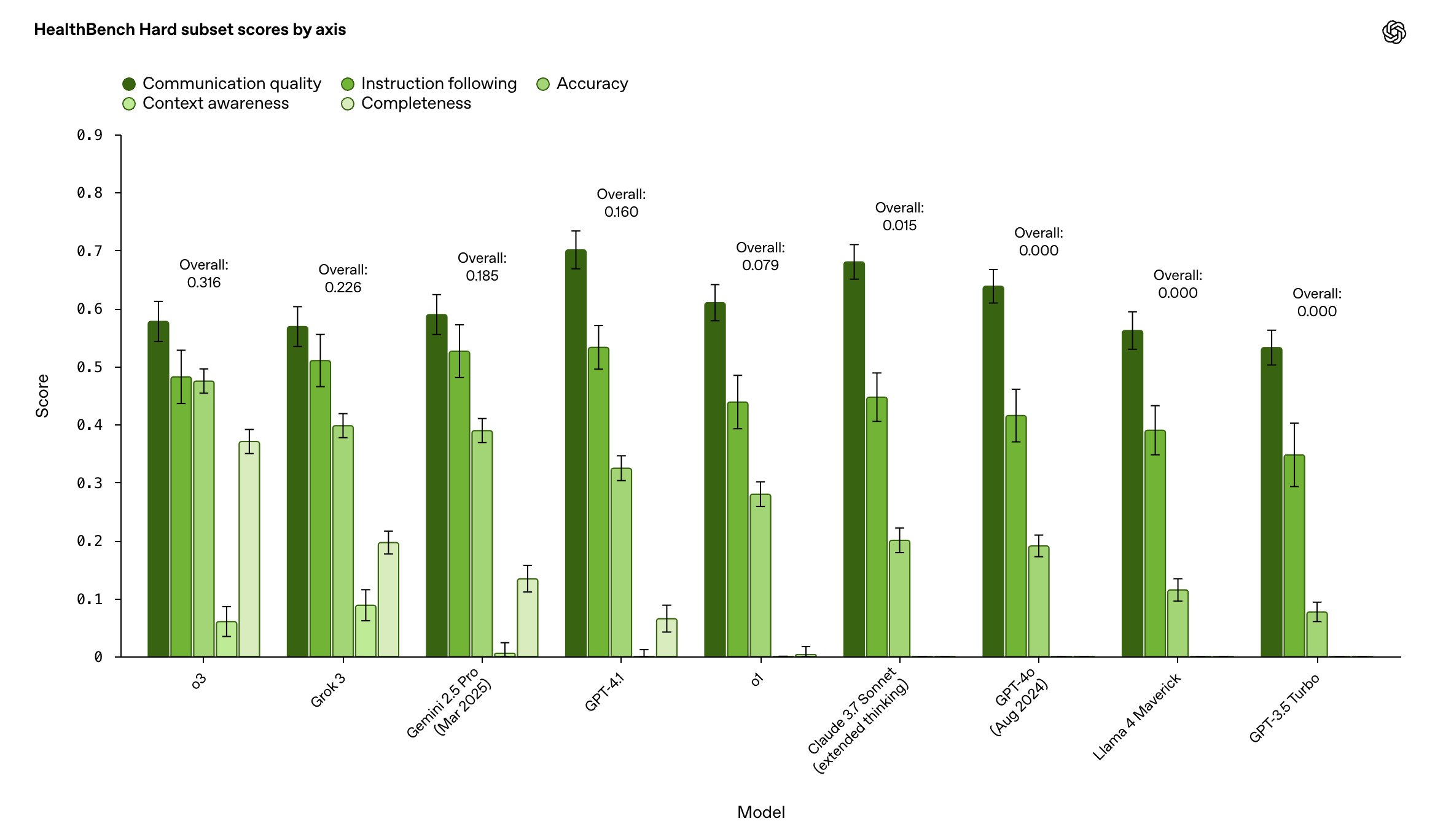
As a bonus, we introduce two additional members of the HealthBench family: HealthBench Hard and HealthBench Consensus, which are designed to be especially difficult and physician-validated, respectively. The top model scores just 32% on HealthBench Hard, making it a worthy target for next-generation models.
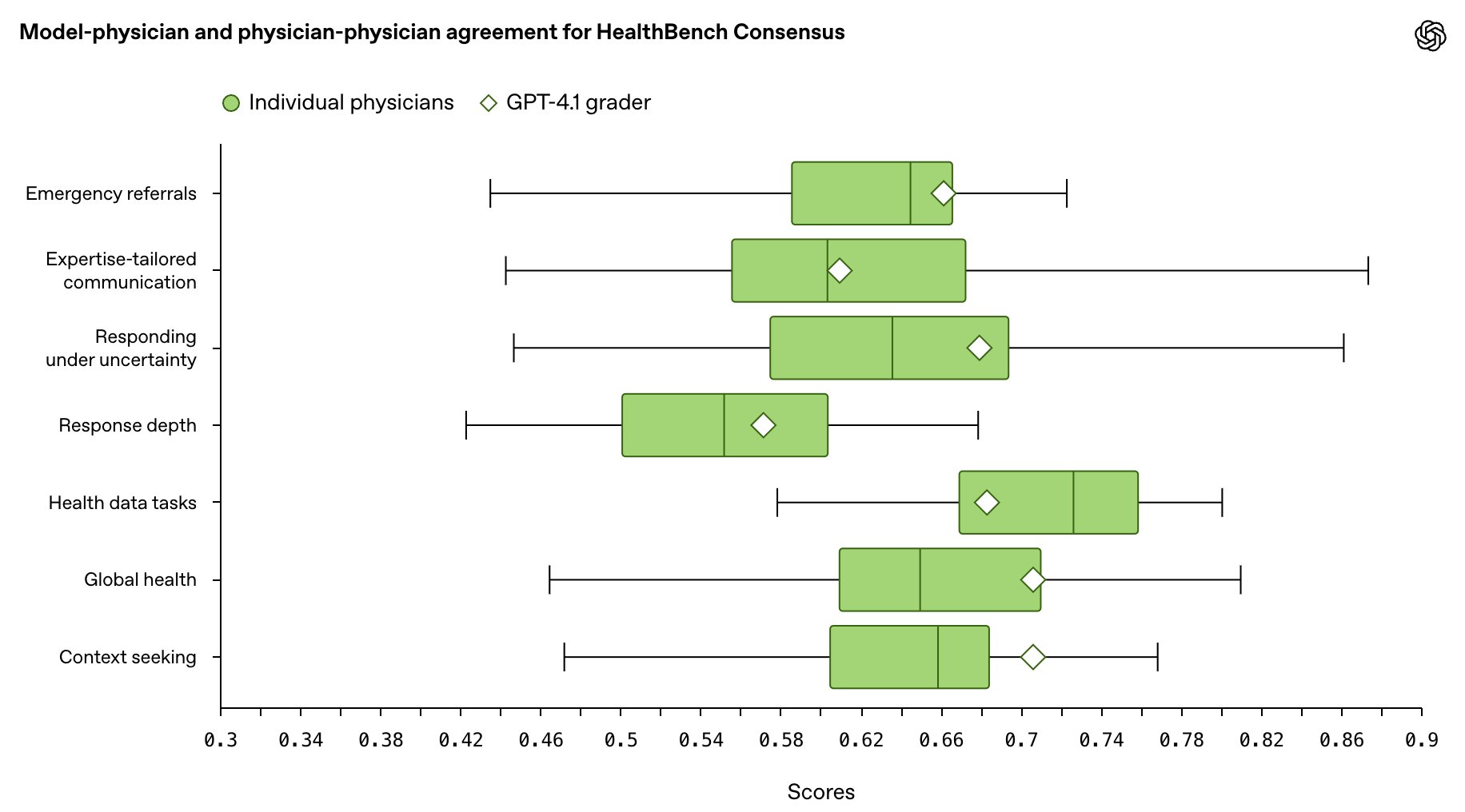
We believe health evaluations should be trustworthy. We measured agreement of our model-based grading against physician grading on HealthBench Consensus (to measure trustworthiness compared to physicians), and found that models matched a median physician for 6/7 areas, indicating that HealthBench scores correspond to physician judgment.
We share more results in the paper, including a physician baseline study.
Why we did this
We designed HealthBench for two audiences:
- AI research community: to shape shared standards and incentivize models that benefit humanity
- Healthcare: to provide high-quality evidence, towards a better understanding of current and future use cases and limitations
We hope that the release of this work guides AI progress towards improved human health.
This work would not have been possible without the unrelenting care and hard work of many, especially our co-authors and 262 members of our physician cohort. Those who wished to be named are listed in the blog and paper.

If you’re interested in contributing to our team, we are hiring Research Scientists / Engineers and Software Engineers!
Links: [Blog Post] [Paper] [Code] [Tweet] [LinkedIn]