There’s been a lot of interest in evaluating frontier large language models (LLMs) for healthcare.
We at OpenAI recently put out HealthBench and found that health performance has doubled between GPT-4o and o3, and our smallest, cheapest model today outperforms our best model from a year ago. Microsoft released their sequential diagnosis (MAI-DxO) work, which found that models produced accurate diagnoses four times as often as physicians. The New York Times reported last year on a study that found that AI outperformed physicians at diagnosis, even when they were assisted by AI.
Evaluations are a bedrock for the clinical AI community—and rightfully so. They are essential for helping the healthcare ecosystem build a clear understanding of AI strengths and limitations—paving the way for safe and effective adoption. They also guide the development of better AI models—we noted when sharing HealthBench that one of our primary motivations was reshaping the incentive landscape for model developers who want to see evaluations improve.
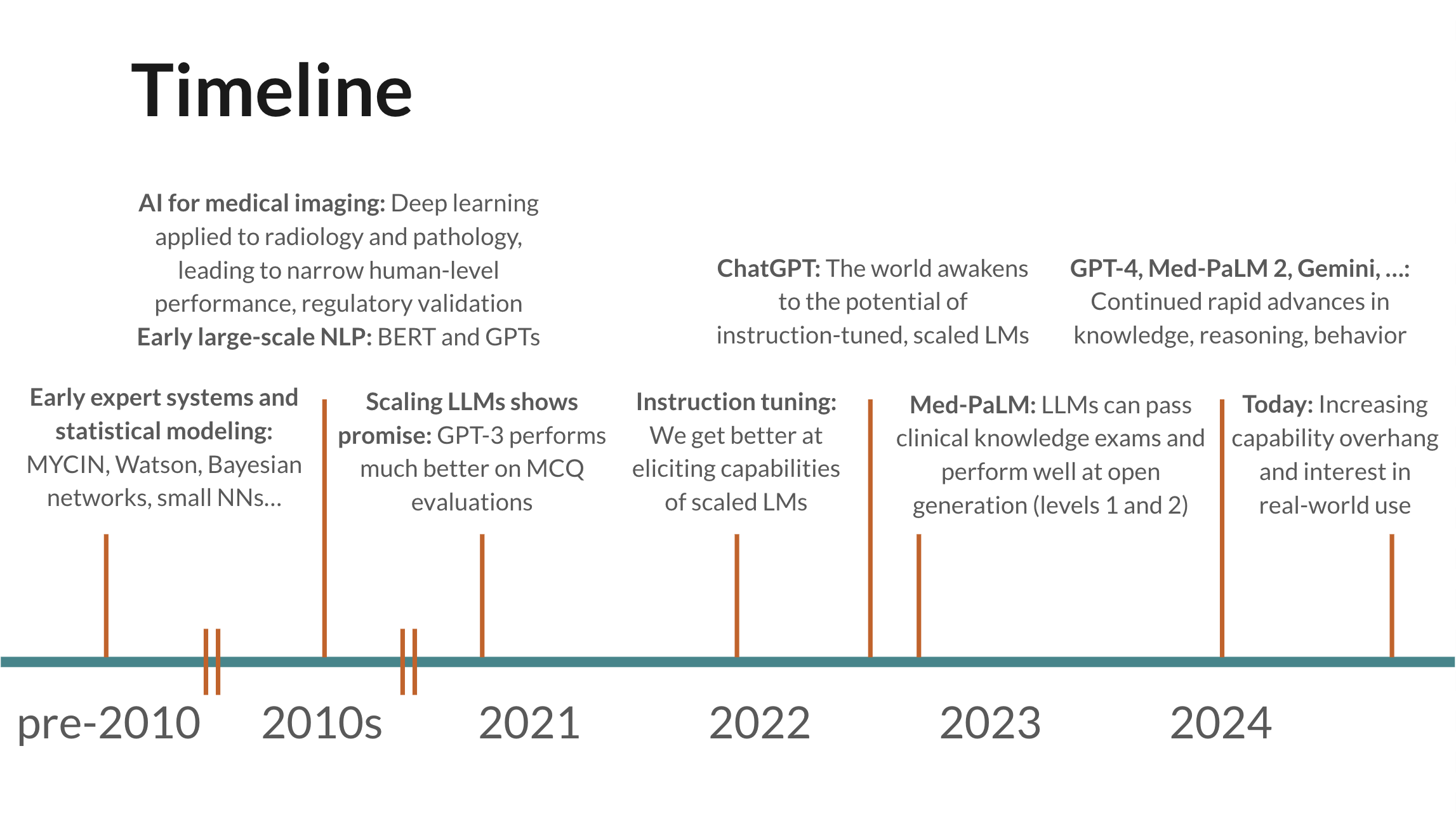
Despite the importance of evaluations, the community has traditionally put too much focus on narrow, unrealistic benchmarks that measure raw model knowledge and capabilities but lack realistic data and use cases. Though we’ve made some progress in more realistic evaluations since early work like Med-PaLM—we spend much less time thinking about multiple-choice exams today—I still think the community could benefit from structured thinking around the kinds of evaluations that will matter most, common pitfalls and methodological issues, and opportunities.
Below, I provide an overview and raw slides from a few talks I gave last year, titled “Levels of Clinical Evaluation for LLMs: Towards More Realistic Evaluations”, after receiving requests to share more widely.
Levels
The talk proposes a taxonomy of the clinical AI evaluation landscape and introduces “Levels” as a useful thinking tool for designing and assessing evaluations. My hope is that sharing this more widely helps the community move more towards realistic, high-quality evaluations that accelerate the impact of AI on human health.
There are four levels, each progressively closer to real-world deployment:

The clinical AI community has focused a lot on Level 1 in the past—this includes multiple-choice exams and producing diagnoses.

Because narrow tasks (e.g., predict diagnosis) lend themselves best to automated assessment, most Level 1 evaluations are very narrow.
There’s still room for more work in Level 1, but mainly in two areas:
- Narrow tasks that remain challenging for today’s models, e.g., some multimodal tasks.
- Broader tasks that are graded automatically using a model-based grader with physician validation. HealthBench shows how this kind of “meta-evaluation” brings the benefits of Levels 2+ while remaining replicable.
Otherwise, unless the goal is to create a replicable evaluation for model developers to use over time, I think we should be doing all of our work beyond Level 1.

Level 2 involves human evaluation of model outputs, typically by physician panels. This enables much broader evaluation of model performance across many tasks and axes, but also has challenges, including confounding factors such as response length and formatting, the cost of physician evaluation, and replication difficulty compared to Level 1. Level 2 studies are fairly common today.

Level 3 builds on Level 2 by using real‑world tasks, often sourced from electronic health record data. Real data often presents unique challenges for performance, safety, and reliability. This is as close as you can get to testing models in real use cases without running a real-world study (Level 4). Level 3 studies are somewhat uncommon but some examples exist.

Level 4 involves putting models into real workflows for clinicians or patients and measuring the real-world effects. This brings its own set of challenges but is crucial for generating real-world evidence and creating clear adoption pathways for the healthcare ecosystem. This research demands significant time and investment; the field needs targeted bets in certain areas, which can rapidly shift the Overton window of the ecosystem. Unfortunately, there have been almost no studies of this kind yet.
The levels are illustrated in more detail through examples in the slides.
Ultimately, to help close the gap between capabilities and implementation, I think the clinical AI community should:
- Prioritize Level 3 and 4 evaluations over Level 1 and 2
- Focus on the highest-value areas for evaluation
- Avoid methodological pitfalls that have weakened previous work
Full slides
Optionally click ‘⋮’ to open speaker notes, which contain more details, definitions, and explanations.
Shorter reference version with a checklist for researchers building evaluations at each level:
Caveats: Please note that as a literature review, these slides are inadequate, because they are both (1) somewhat old (from last year) and (2) selective in their focus. They don’t include some recent works mentioned above, including our own HealthBench (notes). These slides are basically unmodified from last year. They do not reflect the opinions of OpenAI. Any omissions or errors are my own!
Thank you to Rahul Arora, Rebecca Distler, and Robert Korom for early feedback on the slides!
Citation
If you’d like to refer to these slides and content:
Singhal, Karan. "Levels of Clinical Evaluation for LLMs". Karan Singhal (July 2025). https://www.karansinghal.com/notes/levels-of-clinical-evaluation/
BibTeX:
@article{singhal2025levels,
title = {{L}evels of {C}linical {E}valuation for {L}{L}{M}s},
author = {Singhal, Karan},
journal = {karansinghal.com},
year = {2025},
month = {July},
url = "https://www.karansinghal.com/notes/levels-of-clinical-evaluation/"
}